|
I am a second year CS PhD student at Cornell University, advised by Noah Snavely and Bharath Hariharan. Previously, I received my bachelor's in computer science and applied math from Princeton University and worked with Felix Heide. My research focuses on 3D/4D reconstruction and generation. I am supported by the NSF graduate fellowship. Contact: gene@cs.cornell.edu cv / github / linkedin / google scholar / pictures of my cat |

|
|
|

|
Gene Chou, Wenqi Xian, Guandao Yang, Mohamed Abdelfattah, Bharath Hariharan, Noah Snavely, Ning Yu, Paul Debevec ICCV 2025 paper / code / project page We present FlashDepth, a video depth estimation model that processes high-resolution streaming videos in real-time (2044×1148 at 24 FPS on an A100 GPU). |

|
Gene Chou, Kai Zhang, Sai Bi, Hao Tan, Zexiang Xu, Fujun Luan, Bharath Hariharan, Noah Snavely CVPR 2025 paper / project page We propose the task of generating videos from sparse, unposed internet photos, and design a self-supervised method that takes advantage of the consistency of videos and variability of multiview internet photos to train a 3D-aware video model without any 3D annotations such as camera parameters. |

|
Joseph Tung*, Gene Chou*, Ruojin Cai, Guandao Yang, Kai Zhang, Gordon Wetzstein, Bharath Hariharan, Noah Snavely ECCV 2024 paper / code / project page MegaScenes is a scene-level dataset containing 100K SfM reconstructions and 2M registered images, collected from Wikimedia Commons. We validate its effectiveness in training large-scale, generalizable models on the task of single image novel view synthesis. |
|
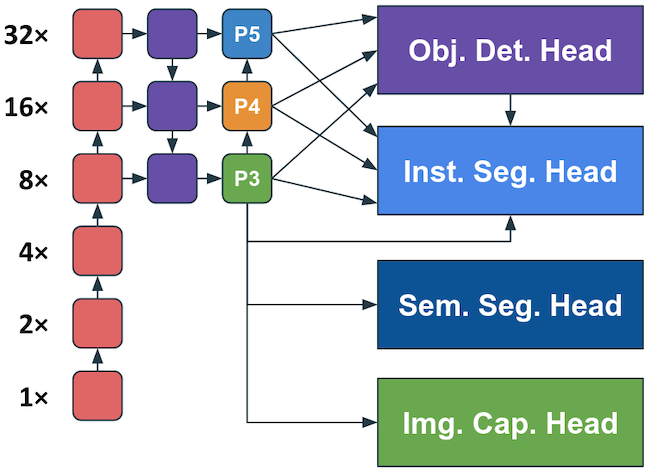
Hung-Shuo Chang, Chien-Yao Wang, Richard Wang, Gene Chou, Hong-Yuan Mark Liao WACV 2025 paper / code Builds on YOLOR to jointly train vision (e.g. object detection, instance and semantic segmentation) and vision-language (e.g. image captioning) tasks. Fast and lightweight while achieving competitive performance. |

|
Praneeth Chakravarthula, Jipeng Sun, Xiao Li, Chenyang Lei, Gene Chou, Mario Bijelic, Johannes Froesch, Arka Majumdar, Felix Heide SIGGRAPH ASIA 2023 paper / project page Recovers images in broadband using a single flat metasurface optic. Compensates for residual aberrations with probabilistic deconvolution implemented using a conditional diffusion model. |

|
Gene Chou, Yuval Bahat, Felix Heide ICCV 2023 paper / code / project page Performs diffusion on the latent space of neural SDFs while providing geometric guidance. Generates diverse meshes conditioned on partial point clouds, 2D images, and real-scanned, noisy point clouds. |


|
Gene Chou, Ilya Chugunov, Felix Heide NeurIPS 2022 paper / code / project page Combines a semi-supervised approach with a self-supervised loss to reconstruct neural SDFs from raw input point clouds of over a hundred unseen object classes. |
|
Website template borrowed from Jon Barron. |